
Trying to understand Transformer Models

The fundamental breakthrough that appears to have led to the current “Cambrian Explosion” around language models was the invention of the Transformer architecture. If I’m understanding it properly, this new way of arranging neural networks dramatically simplified the way we represent contextual information about how a word fits in a sentence, allowing us to encode it in some vectors that can be passed along, which in turn allows these models to take what was once a serial process and parallelize it, running many tokens in parallel at once.

This huge efficiency gain allowed much much larger models to be trained much more rapidly, and as model size has gone up, there have been both predictable improvements and surprising emergent capabilities.
So now I’m trying to understand what these transformer models are and how they work. Here’s what I’ve got so far; if you’re reading this and anything doesn’t sound right please let me know.
Transformer Models
The original paper that introduced the approach is pretty dense, and I found myself reading it multiple times to try to understand what different parts mean. I've found https://jalammar.github.io/illustrated-transformer/ to be the most useful resource to transformer models so far. It is phenomenal, go and read it, it will likely do better than I will in explaining this.
Here's how I'm understanding it: Transformer models have two core pieces, an encoder and a decoder. The encoder's job is to start with an input vector representing a series of tokens, and passes it through a series of steps to attempt to "encode" the relationships between those tokens. These encoded values are stored in three vectors (called the 'query', 'key', and 'value' vectors). The decoder then uses these vector representations to predict new symbols, one at a time.
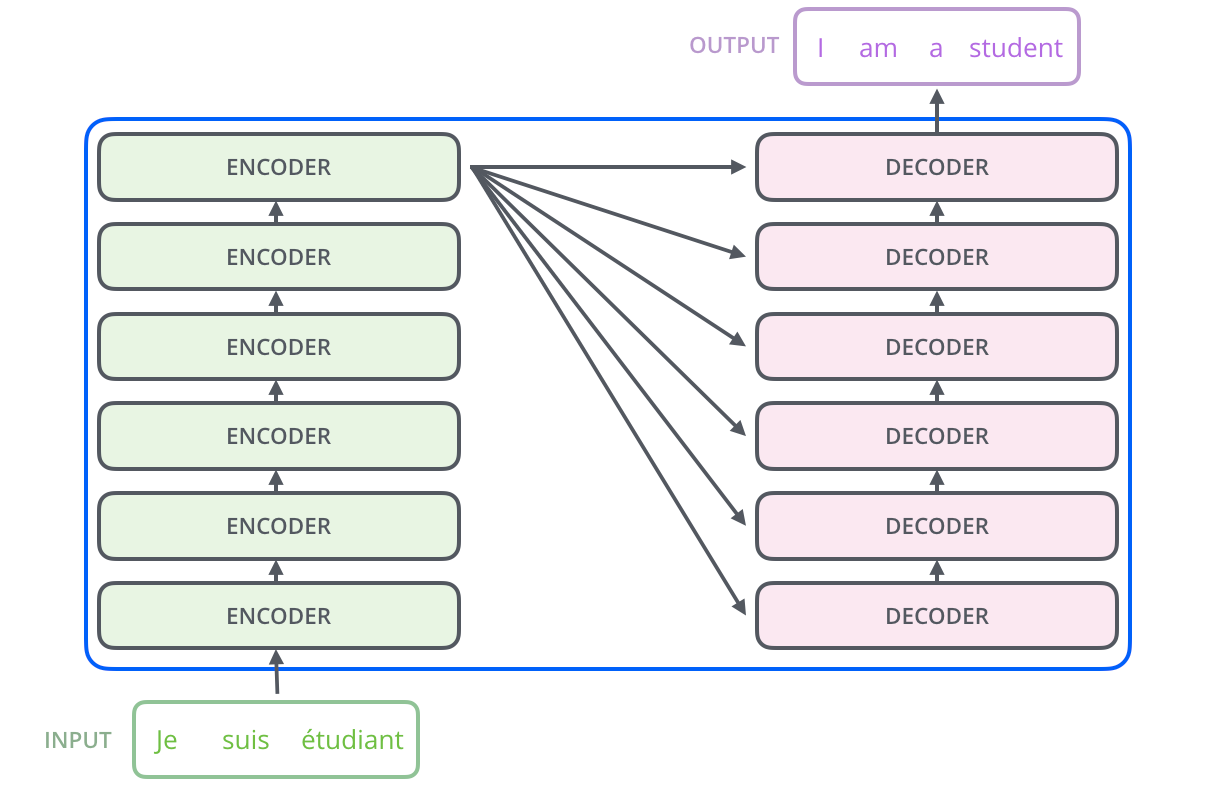
Encoders
The encoder is a stack of identical layers. In the original introduction of the approach, the stack size was 6 layers, though it doesn't seem like that is a "magic" number and it's entirely possible different models might use a different number of layers.
Each layer of the encoder is a feed-forward neural network combined with a 'self-attention layer'. For the first layer it takes in the embedding of your text (essentially a mapping of the original words into a numerical vector space) as the input, while each subsequent layer uses the output of the previous layer as its input.

The self-attention layer takes the vector input and transforms it in three ways using 3 matrices to create 3 new vectors. The value of the matrices are generated as a part of training. For those familiar with other neural network based models, one of these vectors is the direct output of this network layer (called the 'query' in articles about the transformer architecture) while the other two represent hidden state from the neural network (and are called the 'key' and 'value' vectors).
These vectors give a way for the model to understand as it analyzes each symbol (probably a word), the importance of any of the other symbols in the sentence.
For example, if you have a sentence that looks like "I petted my cat and she was very happy", this will allow the model to represent the relevance of "my cat" when analyzing the word "she".
One of the key advances of the transformer model was creating these (relatively) simple representations of how information moves forward from one step to the next through the model, which allows relatively fast computation of a large number of words in parallel. This encoder step essentially turns into a series of wide vector multiplications, which is why GPUs (and TPUs) are the core underlying processing technology that lets these drive forward.
However, because words are run in parallel, the model needs a mechanism to capture their position in the input sentence. This is done using a 'positional' encoding, which is a vector that is computed based on the position of the symbol/word, and added to the word embedding vector before it is processed by the self-attention vector. There have been several proposed positional functions that have been tried in different approaches. The important characteristics of this function are that it generates unique values for each position, and that it is easy to understand "relative" positioning (ie the functions vary continuously based on position). During training, the model will then be able to incorporate these values in its training.
Decoders
The decoder phase is pretty similar to the encoder phase, consisting of a set of stacked layers with attention layers and feed-forward neural networks. The difference is that in a decoder, there are two attention layers before the neural network. The first attention layer is fed any symbols already generated by the transformer. In the first time point, this may be an empty vector, but as it generates symbols these become the "prompt" for each additional step. The second attention layer takes the output of this empty vector and incorporates the "key" and "value" vectors generated by the encoder phases. This allows the model to incorporate all context from the original prompt.

Multiple of these decoders are then stacked. At each layer beyond the first, the input is the output of the previous layer, but the "key" and "value" vectors from the encoder are applied in the same way, allowing every layer of the model to incorporate the encoded prompt.
At the top of the stack, the vector output is run through a process called 'output projection" which consists of very wide linear layer that maps back from the fixed vector size of the transformer into a vector the size of the token library (in English this might be every possible word). This new vector is normalized to a probability distribution, and a single predicted symbol is output (either the most probable, or through some other sampling methodology). Now that you have a new token in the output, the entire decoder stack is run again, with that token (and all previously predicted tokens) as the new input.
Creating your own models
If you're creating your own model, these core "encoder" and "decoder" abstractions are available in standard machine learning libraries such as pytorch and tensorflow. As much as I wanted to know what they were doing, to use them we can treat them as black boxes.
Embedding
One more key concept needed to understand how these things are working under the hood.
Before and after these phases, we need to do some sort of translation between the original form of the input data (human language for a large language model) and the vector representation these models understand. This is done via 'embedding', which is a term used to describe the mapping of any form of input into a vector space. In the case of words, this maps from the series of free text inputs into a vector of continuously varying number values.
There are a variety of embedding algorithms out there, but some of the goals of a good embedding algorithm are to capture semantic similarity (two words with similar meanings should result in similar values in the embedding space) and to have lower dimensionality than raw text (in fact as low a dimension as possible so we can pack the most meaning into a single vector operation)
These embeddings algorithms are themselves often machine learning models that have been trained on a wide range of data.
OpenAI exposes embedding directly as an API. There are also a variety of other options - Langchain includes models for interacting with 13 different embedding approaches as of this writing. If I'm understanding things correctly, for large language models typically these consist of a word/token level embedding added to a positional embedding (to let the model understand where a token is relative to the tokens around it).
Embeddings are the "translation" layer between human language and these deep learning models that are the engines of LLMs like GPT-3 and GPT-4.
Next steps
I’m not sure I need to dig any deeper on transformers themselves; I like having an understanding of how things work, but I’m more interested in applications than in building new models. Next week I’ll be digging into building my first LLM-based application using LangChain.
As always, if something in this article doesn’t match your knowledge or understanding, please let me know! And send me any recommended reading or listening to help me learn faster.